GPT4All 内置的模型库,大部分模型是用的抱脸的网址,通常无法直连下载。 我们这里提出一个手动下载和导入 DeepSeek R1 模型的本地部署方法。本方法的关键是找到 GPT4All 默认的读取路径。 此外,GPT4All 不仅支持独显推理,也可使用 CPU 硬算。 (不过听别处文章评论区说个别模型用独显是不行的,这个这边也没法证实,鄙人手头暂时没有能跑 AI 的独显;个人猜想 DeepSeek R1 应该不会存在这个问题)
-
- 该版本开始已原生支持 DeepSeek R1 深度推理
- 大约需要下载 600 多 MB 的本体包
-
从抱脸或魔搭社区下载 gguf 格式的 DeepSeek R1 模型。
- 这边 12GB 内存 CPU 硬算可以跑 llama8B 和 Qwen7B 这两个模型。
- 请留意找到正确的模型

-
将下载好的 gguf 格式的模型文件放在
%LOCALAPPDATA%\nomic.ai\GPT4All目录- GPT4All 在运行时将自动识别该目录下的模型文件。
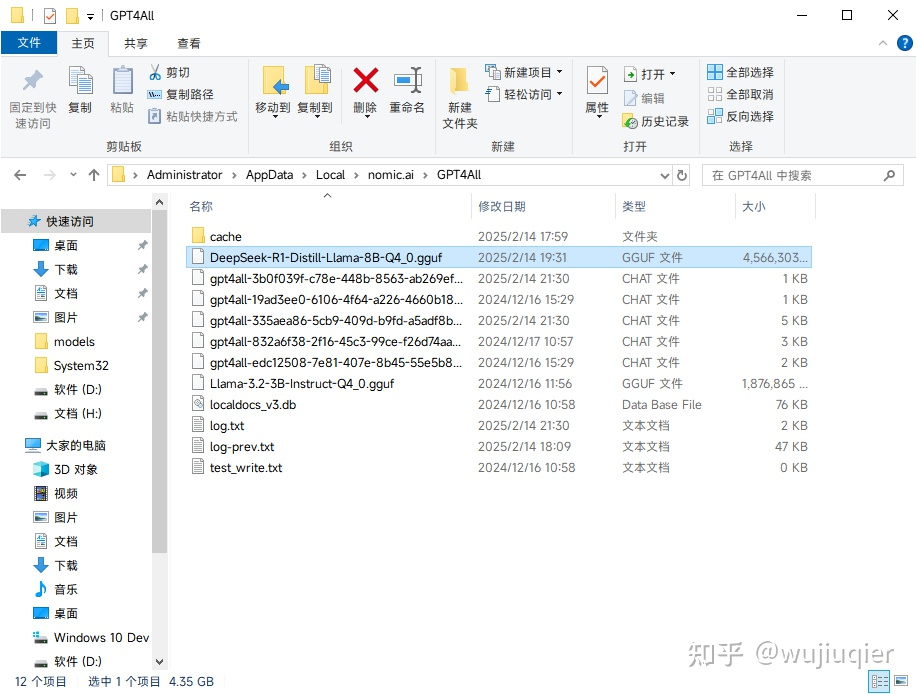
- GPT4All 在运行时将自动识别该目录下的模型文件。
-
打开 GPT4All,从左侧按钮切换到模型界面,看看是否识别到了 DeepSeek
- 首次启动时可能会弹出“匿名使用分析,以改进 GPT4All”和“匿名分享聊天到 GPT4All 数据湖”这两个选项,如果在意数据安全的话应都选择“否”。此项可在设置的“开启数据湖”中找到。
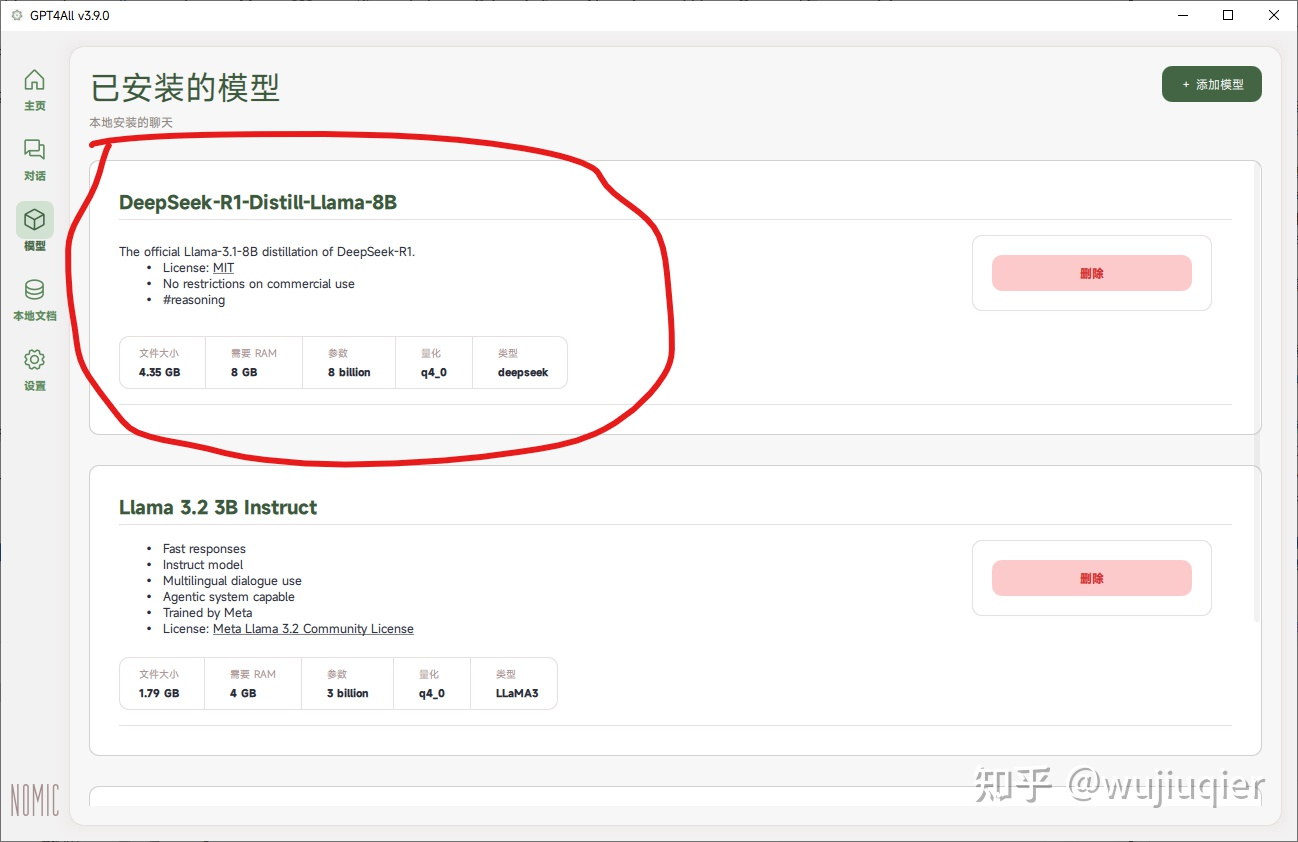
- 首次启动时可能会弹出“匿名使用分析,以改进 GPT4All”和“匿名分享聊天到 GPT4All 数据湖”这两个选项,如果在意数据安全的话应都选择“否”。此项可在设置的“开启数据湖”中找到。
-
如果识别到了,左侧切换到对话,选择下载的 DeepSeek R1 模型,等待加载完毕。然后就可以开始对话了。
- 这边测试使用 i3-6100 CPU 硬算,大概是 2.4 令牌左右每秒。
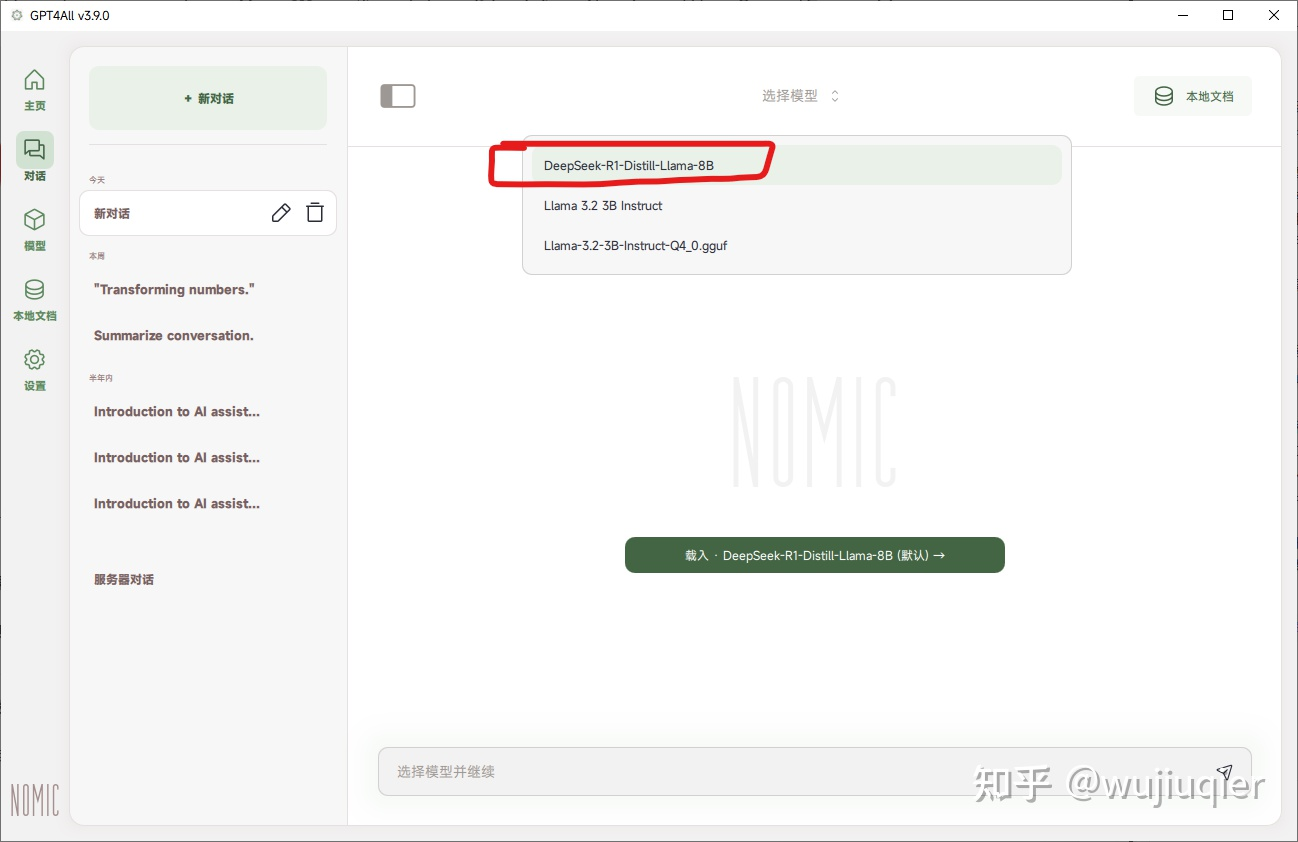
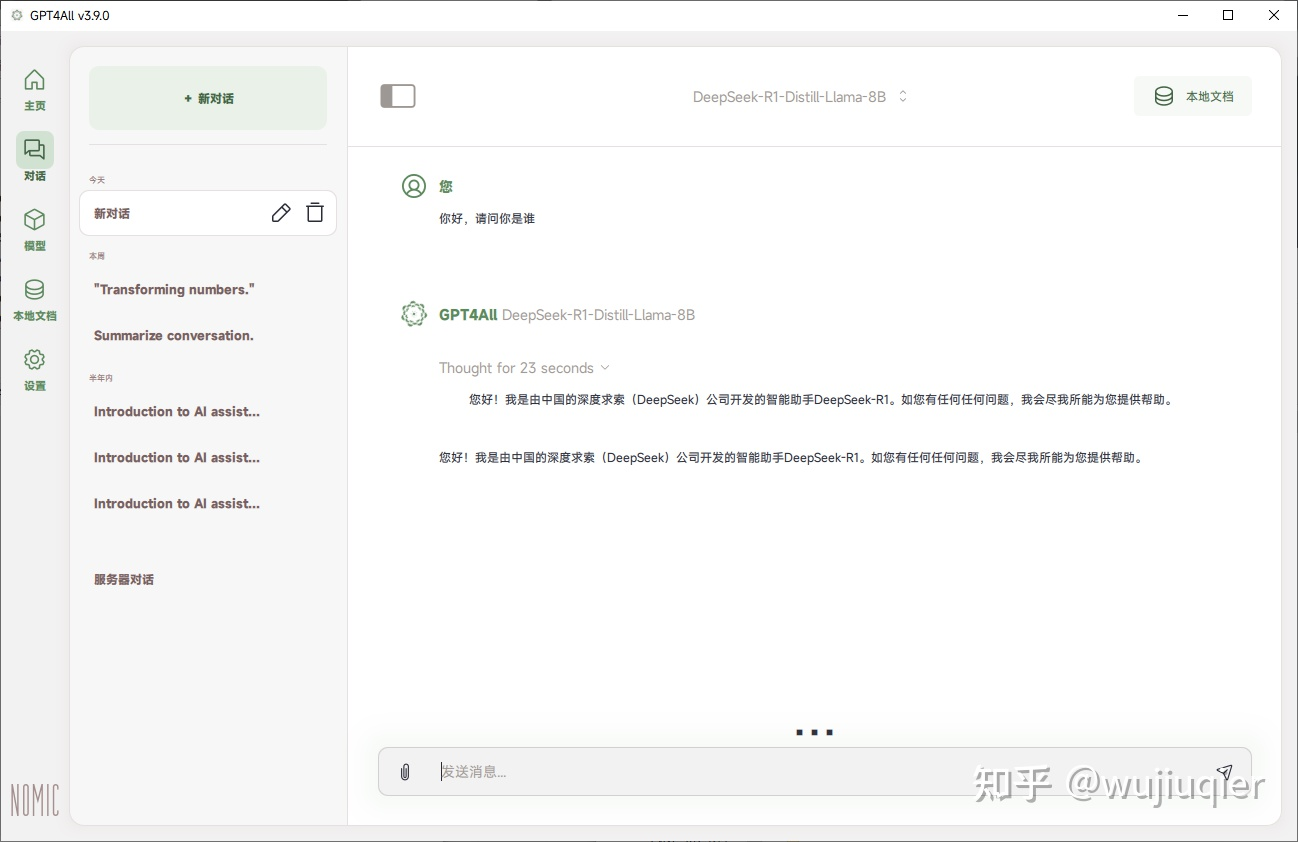
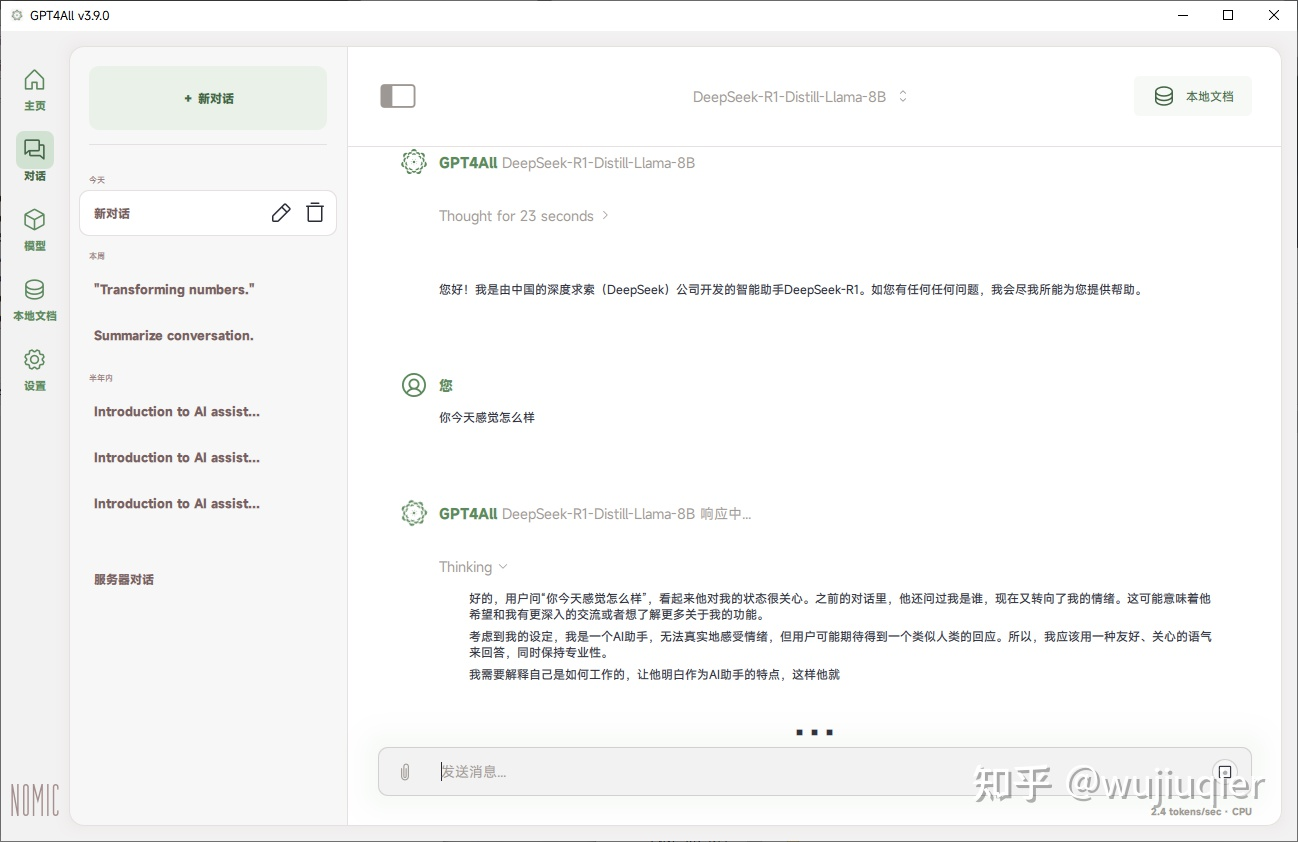
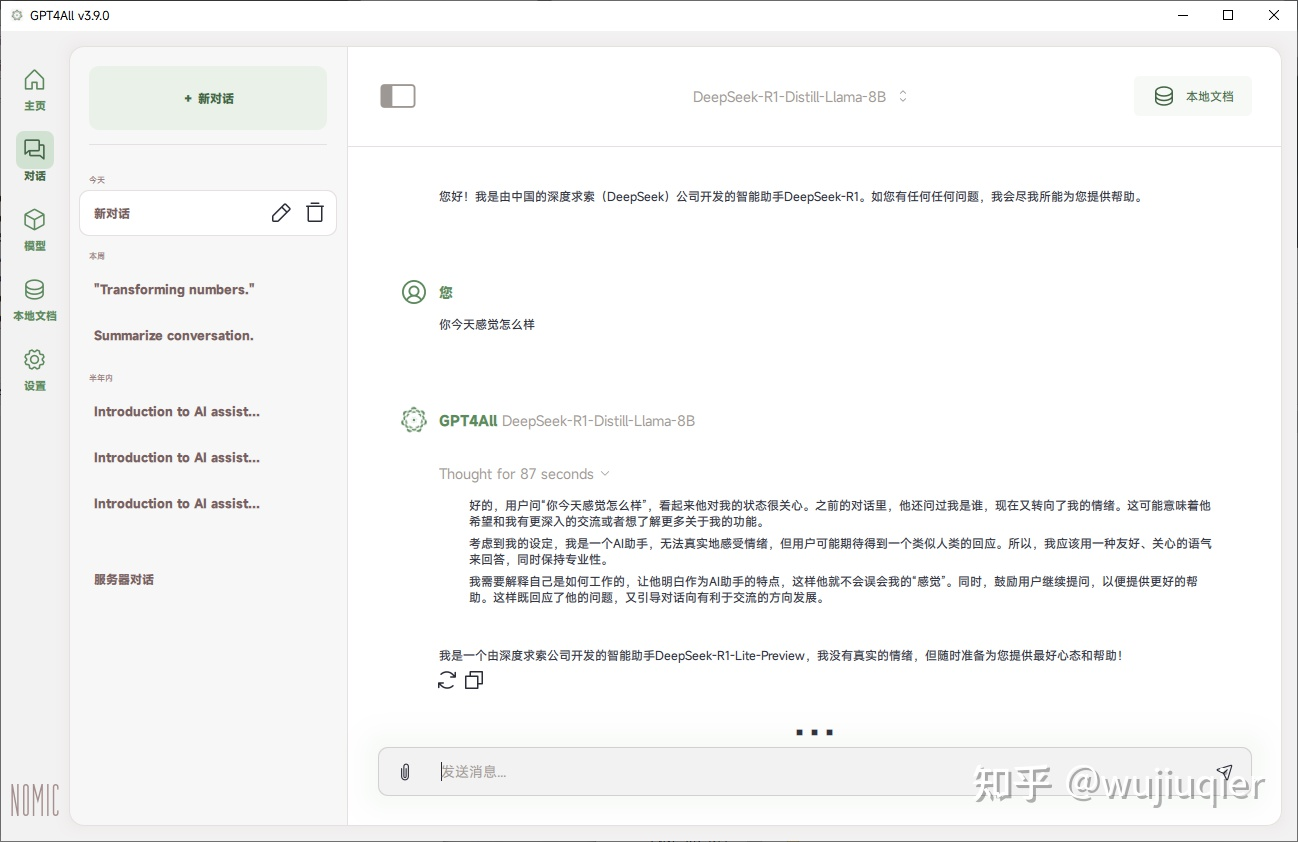
- 这边测试使用 i3-6100 CPU 硬算,大概是 2.4 令牌左右每秒。
